
Hailey's TIL
웹 크롤링 1 본문
1. Web
Server & Client Architecture
- Client
- Request : Browser를 사용하여 Server에 데이터를 요청
- Server
- Response : Client의 Browser에서 데이터를 요청하면 요청에 따라 데이터를 Client로 전송
HTTP Request Methods
- Get
- URL에 Query 포함
- Query(데이터) 노출, 전송 가능 데이터 작음
- Post
- Body에 Query 포함 • Query(데이터) 비노출, 전송 가능 데이터 많음
HTTP Status Code
- Client와 Server가 데이터를 주고받은 결과 정보
- 2xx - Success
- 3xx - Redirect
- 4xx - Request Error
- 5xx - Server Error
Cookie, Session, Cache
- Cookie
- Client의 Browser에 저장하는 문자열 데이터
- 로그인 정보, 내가 봤던 상품 정보, 팝업 다시보지 않음 등
- Session
- Client의 Browser와 Server의 연결 정보
- 자동 로그인
- Cache
- Client, Server의 RAM(메모리)에 저장하는 데이터
- RAM에 데이터를 저장하면 데이터 입출력이 빠름
Scraping & Crawling
- Scraping
- 특정 데이터를 수집하는 작업
- Crawling
- 웹서비스의 여러 페이지를 이동하며 데이터를 수집하는 작업
- spider, web crawler, bot 용어 사용
2. Web Crawing
- 웹 페이지에서 데이터를 수집
✅ 웹크롤링 방법
1. 웹페이지의 종류
- 정적인 페이지 : 웹 브라우져에 화면이 한번 뜨면 이벤트에 의한 화면의 변경이 없는 페이지
- 동적인 페이지 : 웹 브라우져에 화면이 뜨고 이벤트가 발생하면 서버에서 데이터를 가져와 화면을 변경하는 페이지
2. requests 이용
- 받아오는 문자열에 따라 두가지 방법으로 구분
- json 문자열로 받아서 파싱하는 방법 : 주로 동적 페이지 크롤링할 때 사용 -> url 안 바뀜
- html 문자열로 받아서 파싱하는 방법 : 주로 정적 페이지 크롤링할 때 사용 -> url 바뀜
3. selenium 이용
- 브라우져를 직접 열어서 데이터를 받는 방법
4. 크롤링 방법에 따른 속도
- requests json > requests html > selenium
Crawling Naver Stock Data
- 네이버 증권 사이트에서 주가 데이터 수집
- 수집할 데이터 : 일별 kospi, kosdaq 주가, 일별 환율(exchange rate) 데이터
- 데이터 수집 절차
- 웹서비스 분석 : url
- 서버에 데이터 요청 : request(url) > response : json(str)
- 서버에서 받은 데이터 파싱(데이터 형태를 변경) : json(str) > list, dict > DataFrame
import warnings
warnings.filterwarnings('ignore') # 경고 문구 출력 x
import pandas as pd
import requests
1. 웹서비스 분석 : url
- pc 웹페이지가 복잡하면 mobile 웹페이지에서 수집
page, page_size = 1, 60
url = f'https://m.stock.naver.com/api/index/KOSPI/price?pageSize={page_size}&page={page}'
print(url)
⚠️status code 가 403이 나온다면? -> 헤더 설정하기!
# 예시
# 1. URL
url = 'https://finance.daum.net/api/exchanges/summaries'
# header 설정
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36','Referer': 'https://finance.daum.net',
'Referer': 'https://finance.daum.net/exchanges' ,
}
# 2. request > response : json(str)
response = requests.get(url, headers=headers)
response
*️⃣ pc 페이지를 모바일 페이지로 변경하기

개발자 도구 -> 모바일 변환 버튼 클릭 -> url 다시 엔터 => 모바일모드 변경 완료!
2. 서버에 데이터 요청 : request(url) > response : json(str)
- response의 status code가 200이 나오는지 확인
- 403이나 500이 나오면 request가 잘못되거나 web server에서 수집이 안되도록 설정이 된 것임
- header 설정 또는 selenium 사용
- 200이 나오더라도 response 안에 있는 내용을 확인 > 확인하는 방법 : response.text
response = requests.get(url)
response.text[:50] # datatype : str
3. 서버에서 받은 데이터 파싱(데이터 형태를 변경) : json(str) > list, dict > DataFrame
data= response.json() #str -> list, dict
df = pd.DataFrame(data) # list. dict -> DataFrame
columns = ['localTradedAt', 'closePrice']
df = df[columns]
df.head(2)
4. 함수로 만들기
def stock_price(page_size = 60, page = 1):
# 1. 웹서비스분석 : URL
url = f'https://m.stock.naver.com/api/index/KOSPI/price?pageSize={page_size}&page={page}'
# 2. request(URL) > response(JSON) : JSON(str)
response = requests.get(url)
# 3. JSON(str) -> list, dict > DataGrame : Data
return pd.DataFrame(response.json())[["localTradedAt", "closePrice"]]
df = stock_price()
df.tail(2)
df = stock_price('KOSDAQ')
df.tail(2)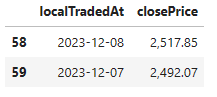

5. 원달러 환율 데이터 수집
def exchange_rate(code="FX_USDKRW", page=1, page_size=60):
url = f'https://m.stock.naver.com/front-api/v1/marketIndex/prices?page={page}\
&category=exchange&reutersCode={code}&pageSize={page_size}'
response = requests.get(url)
columns = ["localTradedAt", "closePrice"]
data = response.json()['result']
return pd.DataFrame(data)[columns]
6. 시각화
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 수집
page_size = 60
kospi_df = stock_price("KOSPI", page_size=page_size)
kosdaq_df = stock_price("KOSDAQ", page_size=page_size)
usd_df = exchage_rate("FX_USDKRW", page_size=page_size)
kosdaq_df["kosdaq"] = kosdaq_df["closePrice"].apply(lambda data: float(data.replace(",", "")))
usd_df["usd"] = usd_df["closePrice"].apply(lambda data: float(data.replace(",", "")))
kosdaq_df = kosdaq_df.drop(columns=["closePrice"])
usd_df = usd_df.drop(columns=["closePrice"])
# 데이터 전처리 2 : 날짜 데이터 맞추기
mergemerge_df_1 = pd.merge(kospi_df, kosdaq_df, on="localTradedAt")
merge_df_2 = pd.merge(merge_df_1, usd_df, on="localTradedAt")
merge_df = merge_df_2.copy()
merge_df.tail(2)
데이터 시각화
# 시각화
plt.figure(figsize=(20, 5))
# plt.plot(merge_df["localTradedAt"], merge_df["kospi"], label="kospi")
# plt.plot(merge_df["localTradedAt"], merge_df["kosdaq"], label="kosdaq")
# plt.plot(merge_df["localTradedAt"], merge_df["usd"], label="usd")
columns = merge_df.columns[1:]
for column in columns:
plt.plot(merge_df["localTradedAt"], merge_df[column], label=column)
xticks_count = 11
plt.xticks(merge_df["localTradedAt"][::int(len(merge_df) // xticks_count) + 1])
plt.legend(loc=0)
plt.show()
-> 스케일이 달라서 비교하기 힘들다 => 스케일링!
7. 데이터 스케일링
- min max scaling : 모든 데이터를 최솟값은 0 최댓값은 1로 바꿔서 데이터 출력

from sklearn.preprocessing import minmax_scale
# 시각화
plt.figure(figsize=(20, 5))
columns = merge_df.columns[1:]
for column in columns:
plt.plot(merge_df["localTradedAt"], minmax_scale(merge_df[column]), label=column)
xticks_count = 11
plt.xticks(merge_df["localTradedAt"][::int(len(merge_df) // xticks_count) + 1])
plt.legend(loc=0)
plt.show()
8. 상관관계 분석
- 피어슨 상관계수(Pearson Correlation Coefficient)
- 두 데이터 집합의 상관도를 분석할 때 사용되는 지표
- 상관계수의 해석
- -1에 가까울수록 서로 반대방향으로 움직임
- 1에 가까울수록 서로 같은 방향으로 움직임
- 0에 가까울수록 두 데이터는 관계가 없음
# 해석 1 : kospi, kosdaq은 아주 강한 양의 상관관계를 갖는다. (데이터가 같은 방향으로 움직임)
# 해석 2 : kospi와 usd를 강한 음의 상관관계를 갖는다. (데이터가 반대 방향으로 움직임)
corr_df = merge_df[merge_df.columns[1:]].corr()
corr_df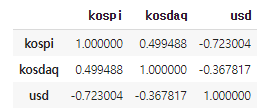
# 결정계수 : r-squared
# 1과 가까울수록 강한 관계, 0과 가까울수록 약한 관계
plt.figure(figsize=(20, 5))
sns.heatmap(corr_df**2, cmap="YlGnBu", annot=True)
plt.show()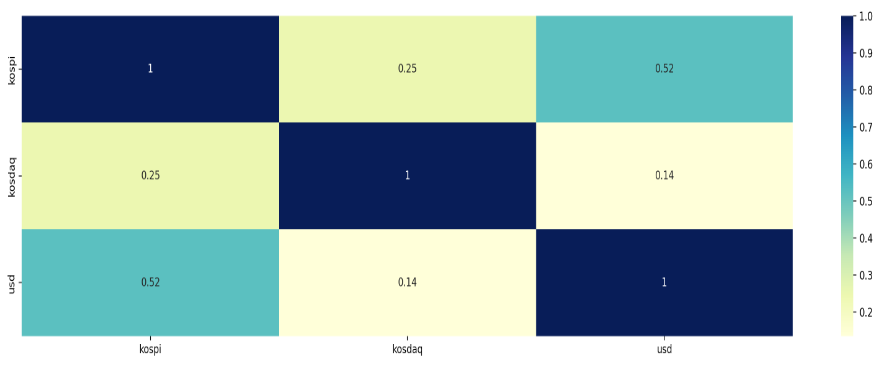
3. REST API
- Representational State Transfer
- Client와 Server가 통신하기 위한 URL 구조에 대한 정의 및 디자인
KAKAO API
1) request token 얻기
- https://developers.kakao.com/
- 내 애플리케이션 > 애플리케이션 추가
2) KoGPT
- 문서 > KoGPT > REST API
- tokens : 공백을 제외한 글자수
# 1. URL
url = 'https://api.kakaobrain.com/v1/inference/kogpt/generation'
prompt = '원자폭탄을 발명한 사람은'
headers = {'Authorization': f'KakaoAK {REST_API_KEY}', 'Content-Type': 'application/json'}
params = {'prompt': prompt, 'max_tokens': 50, 'temperature': 0.3, 'n': 2}
# 2. request > response
response = requests.post(url, json.dumps(params), headers=headers)
response
# 3. parsing
results = response.json()
results = results['generations']
results = [result['text'] for result in results]
results
# 함수만들기
def kogpt_api(prompt, command='', max_tokens=128, temperature=1, n=1):
headers = {'Authorization': f'KakaoAK {REST_API_KEY}', 'Content-Type': 'application/json'}
params = {'prompt': prompt + command, 'max_tokens': max_tokens, 'temperature': temperature, 'n': n}
response = requests.post(url, json.dumps(params), headers=headers)
results = response.json()
results = results['generations']
return [result['text'] for result in results]
[3주 차 01]
'AI' 카테고리의 다른 글
| 머신러닝 - 데이터 전처리 (0) | 2024.03.13 |
|---|---|
| 웹 크롤링 2 (0) | 2024.03.09 |
| 데이터 분석 및 의미 찾기 2 (0) | 2024.02.29 |
| 데이터 분석 및 의미 찾기 1 (2) | 2024.02.28 |
| 데이터 처리 2 (1) | 2024.02.27 |
'AI' Related Articles
more



